It works for the blog page and also works when I navigate to the individual blog posts, but when I access the blog posts inside a foreach loop, they just grab the data from the blog instead of the individual posts, as shown below.
The only page with "test" for the description is the blog, which is also the only place that has a description entered manually. The blog posts are mapped to a separate "summary" property using seo checker's document type settings panel. Here is a screenshot of seo data for the first blog post, which doesn't match what is pulled by the foreach loop.
Yeah, this would be nice to have for v2. I had wanted to take advantage of seo checker's doc type property mappings for this, but I can work around this issue.
Wrong meta data gathered when pulling from page other than the current one
Umbraco Version: 7.6.3
SEO Checker Version: 10.0.1
I'm trying to create an rss feed using meta data stored by seo checker, but it isn't pulling the correct information. Here is the code I am using
It works for the blog page and also works when I navigate to the individual blog posts, but when I access the blog posts inside a foreach loop, they just grab the data from the blog instead of the individual posts, as shown below.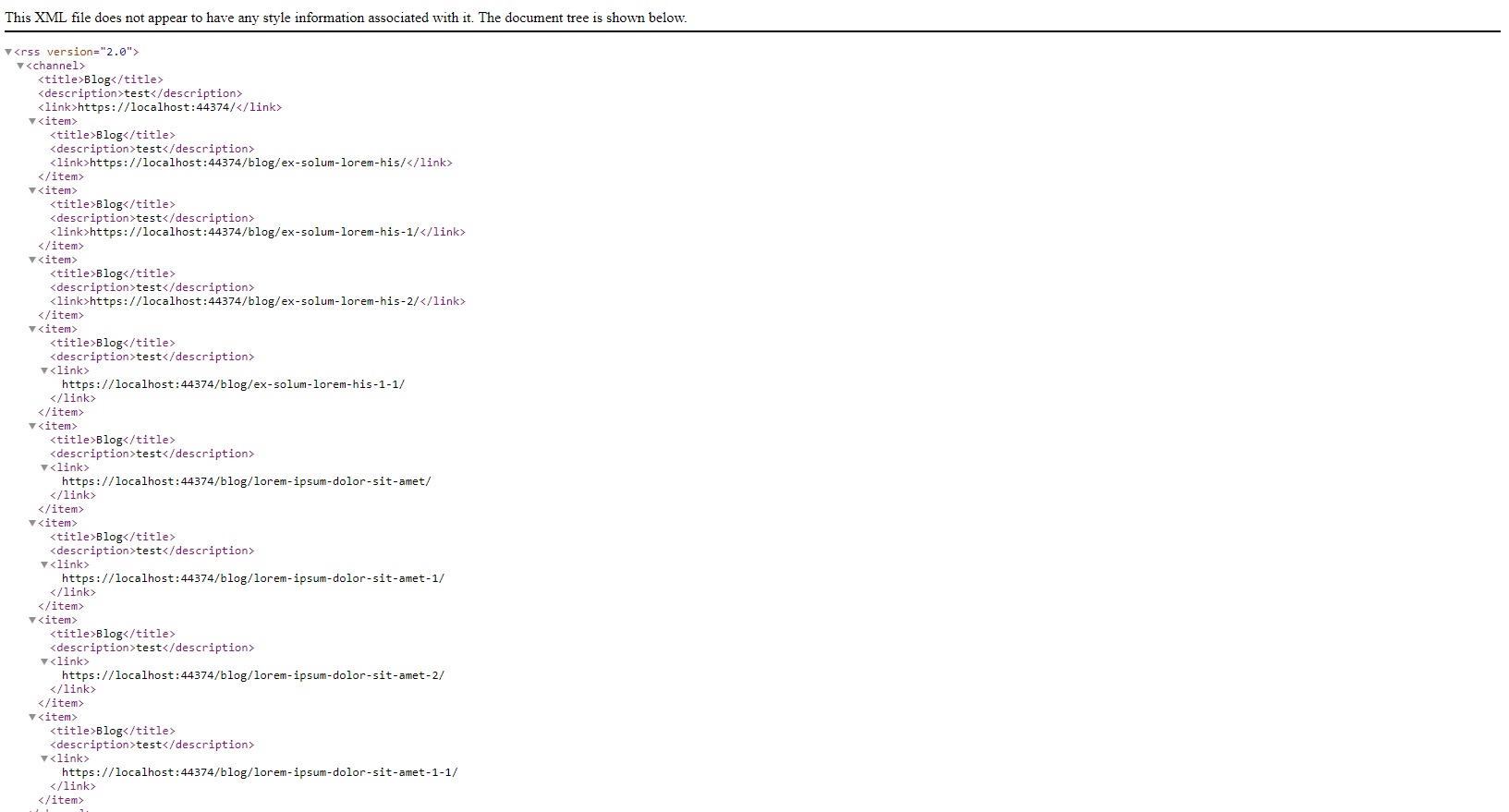
The only page with "test" for the description is the blog, which is also the only place that has a description entered manually. The blog posts are mapped to a separate "summary" property using seo checker's document type settings panel. Here is a screenshot of seo data for the first blog post, which doesn't match what is pulled by the foreach loop.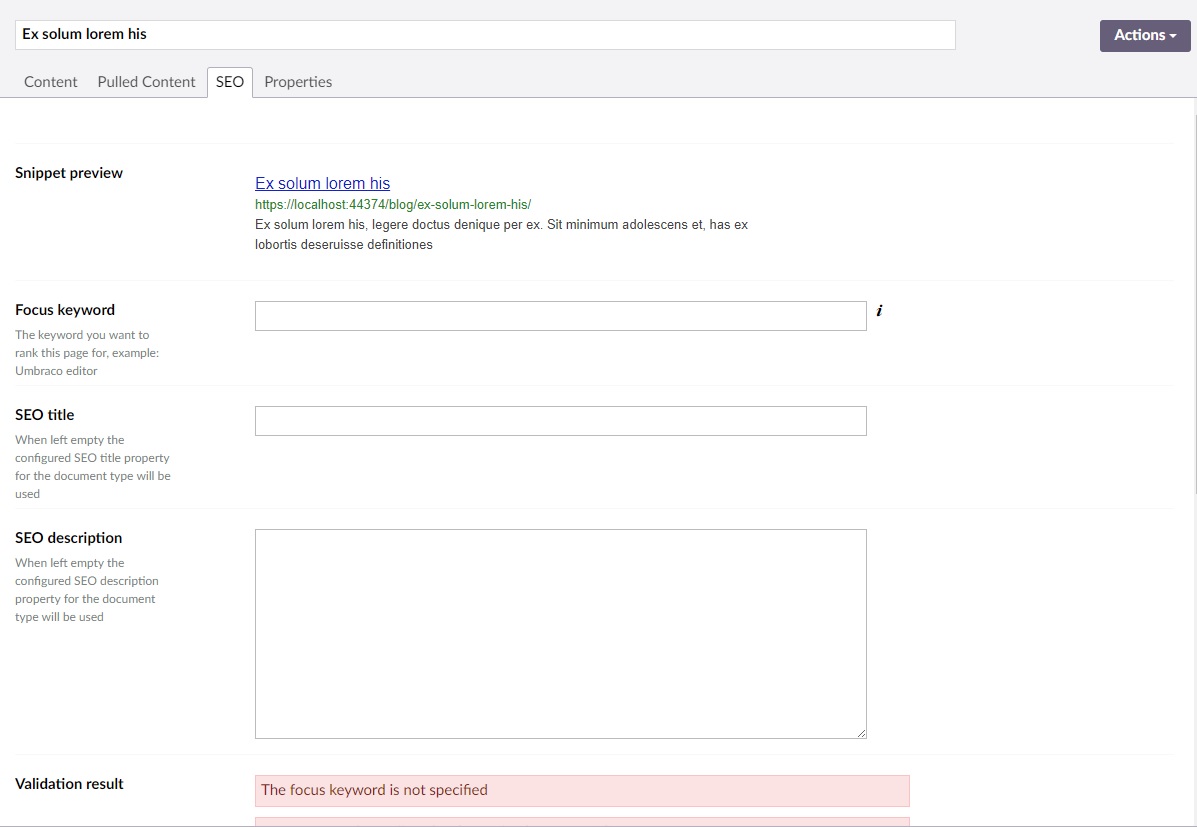
Hi Jesse,
This is by design. SEOChecker needs the context of the page to render all metadata. Maybe it will change for v2.
Best,
Richard
Yeah, this would be nice to have for v2. I had wanted to take advantage of seo checker's doc type property mappings for this, but I can work around this issue.
is working on a reply...